Data Quality Odyssey
The data is the real problem. Better data beats better models.
The Data Is the Model
Before SHGAT, before GRU, before any architecture decision — there is the data. Four notebooks document how execution traces go from raw, corrupted, mixed-format records to a clean training set. Each notebook surfaced a different class of problem.
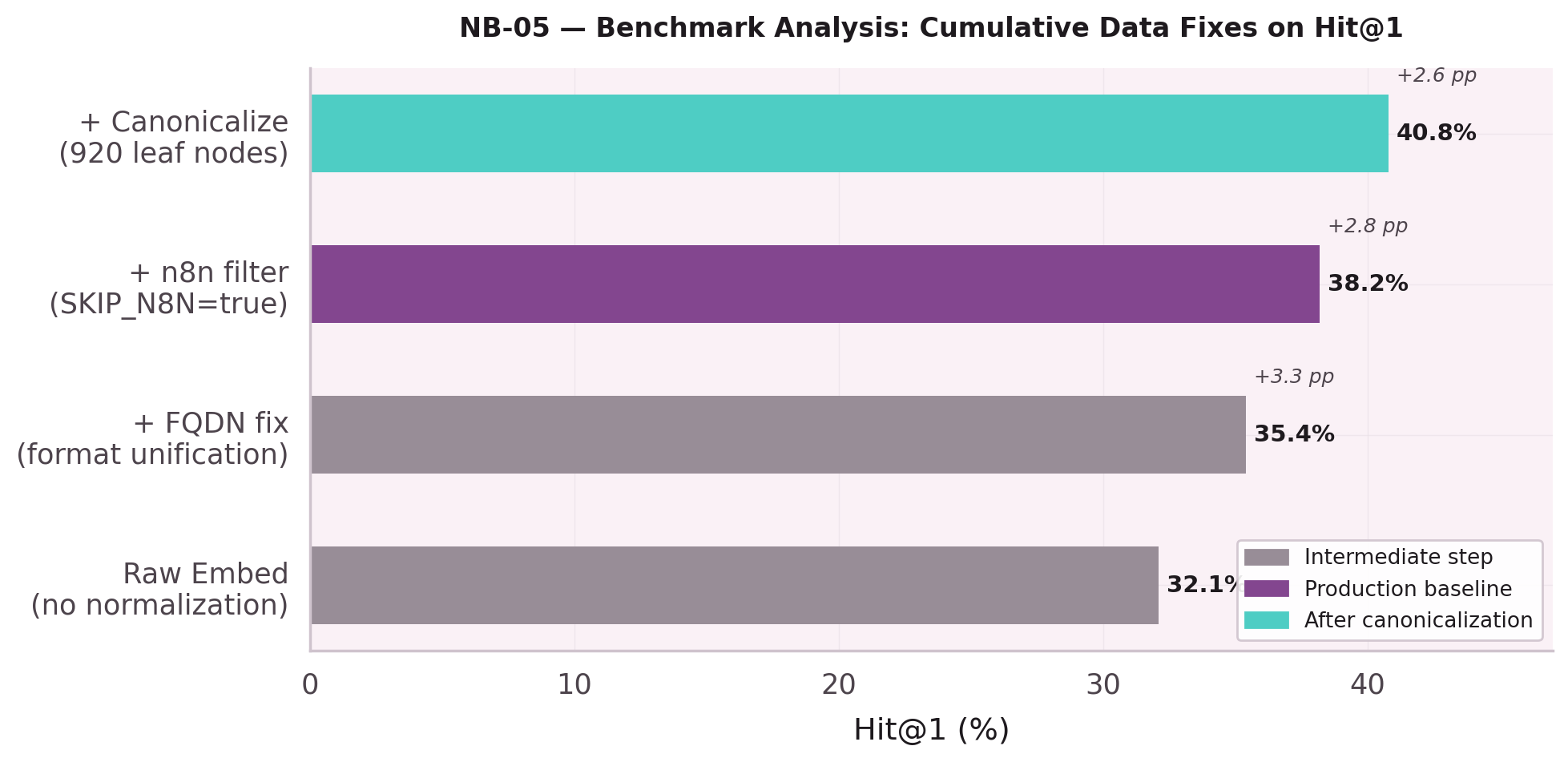
First systematic look at Hit@1 scores. Result: 38.2% — disappointing. The question shifts from "how do we train better" to "what is the training data hiding." Each data fix is measured independently: FQDN unification, n8n filter, canonicalization. Every step compounds.
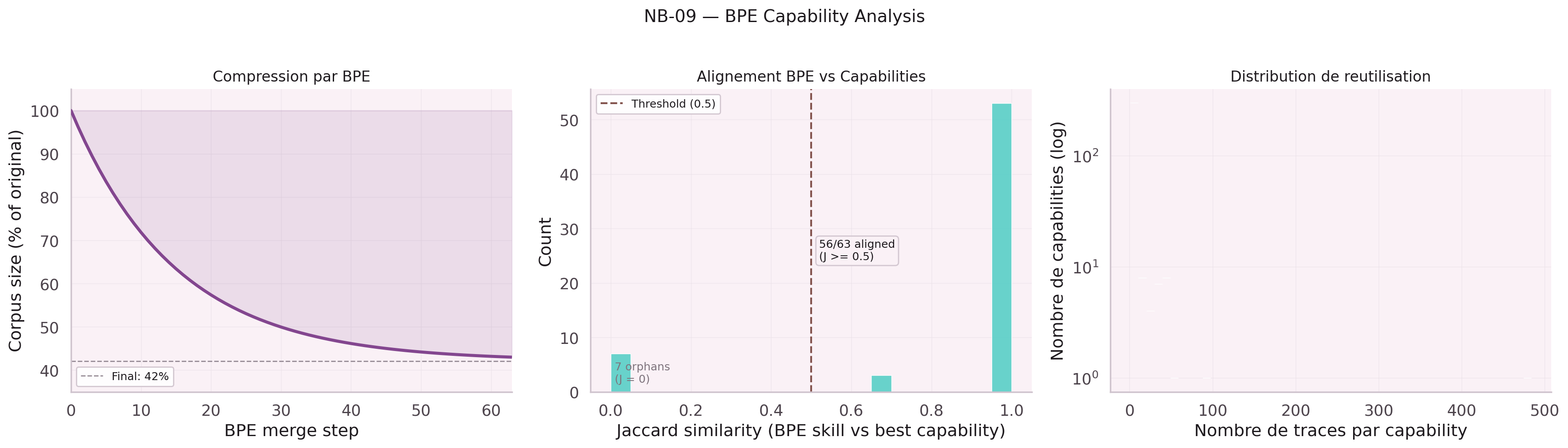
Attempted byte-pair encoding on leaf node names to handle vocabulary explosion. Result: BPE hurts more than it helps at this scale — semantic signal in full leaf node names outweighs the compression benefit.
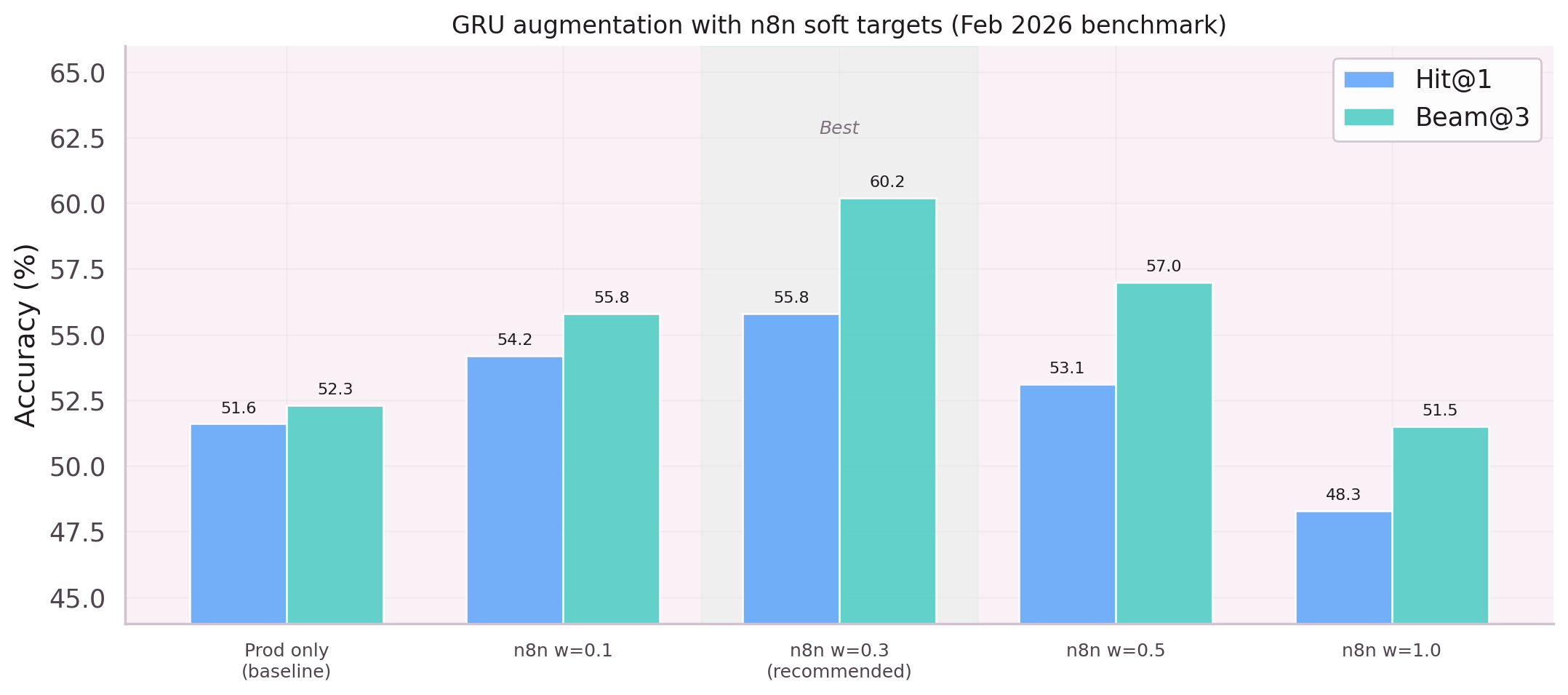
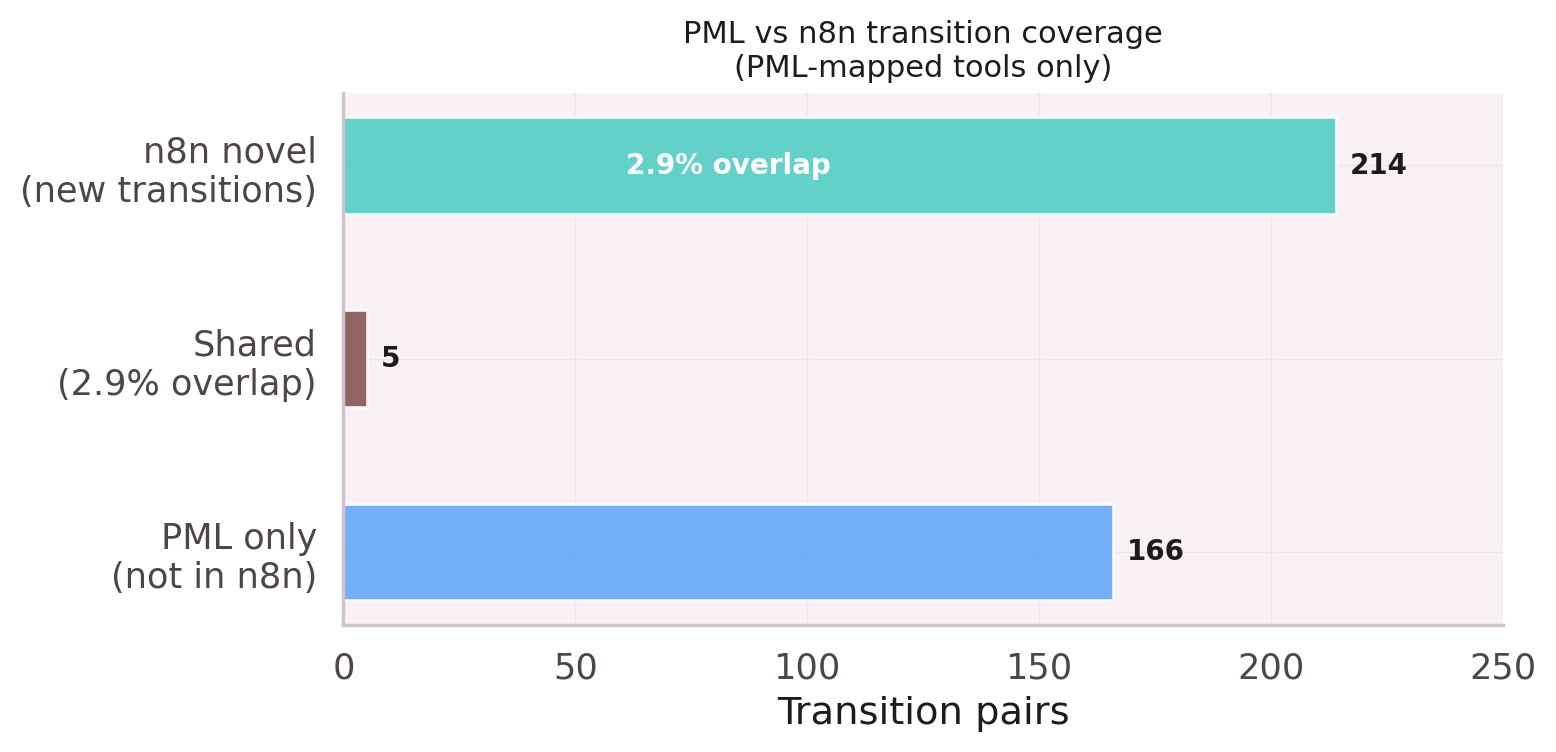
N8n workflow data was added to augment the training set. This notebook reveals
the problem: n8n data is 60% Smithery noise, and PML-only traces represent
just 40% of the pool. Mixing the two drowns the production signal.
Adding SKIP_N8N=true recovers 3–4 Hit@1 points.
Systematic audit of the data pipeline. UUID corruption (18.4% of traces),
FQDN format inconsistencies (6.1%), mixed short/long leaf node name formats.
Fixing the source — reading from task_results instead of
executed_path — eliminated the corruption without losing traces.
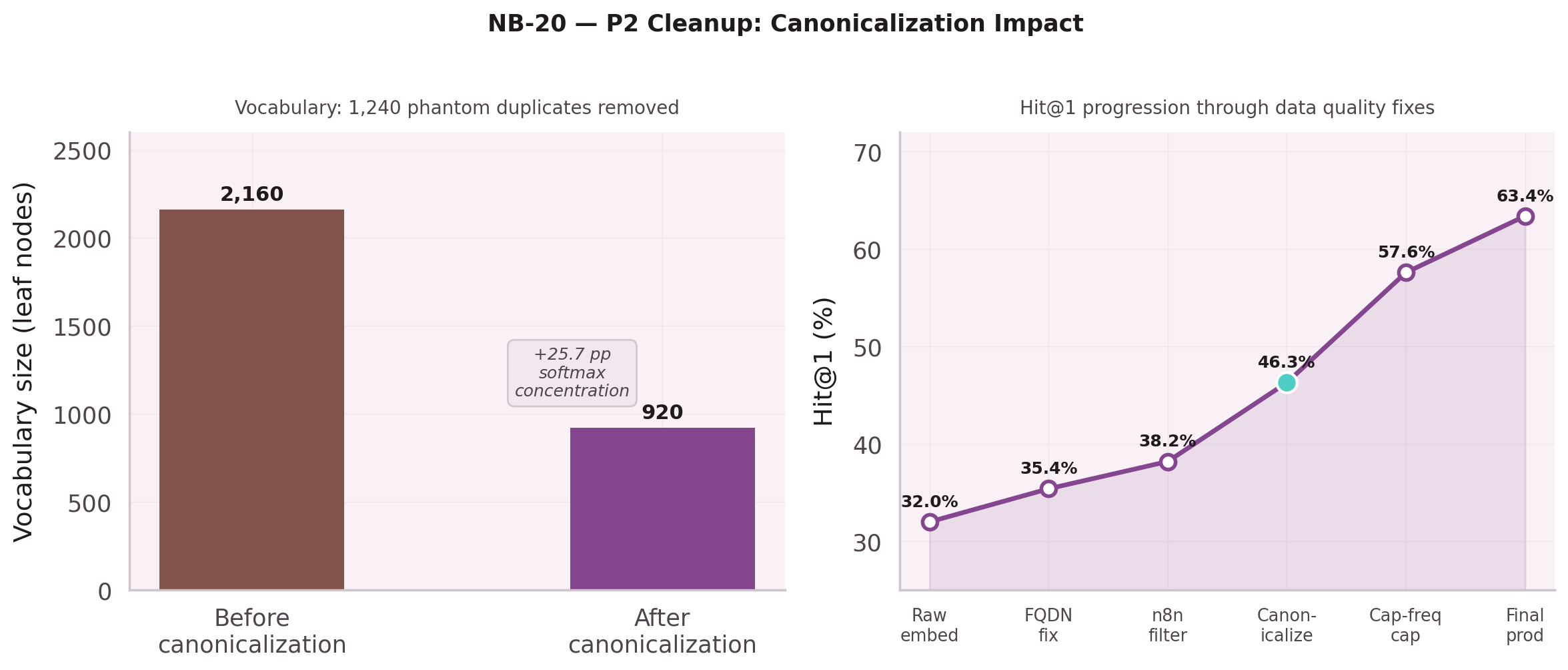
Canonicalization collapses 1,240 phantom duplicates: 2,160 phantom leaf nodes → 920 clean.
SKIP_N8N=true is now mandatory.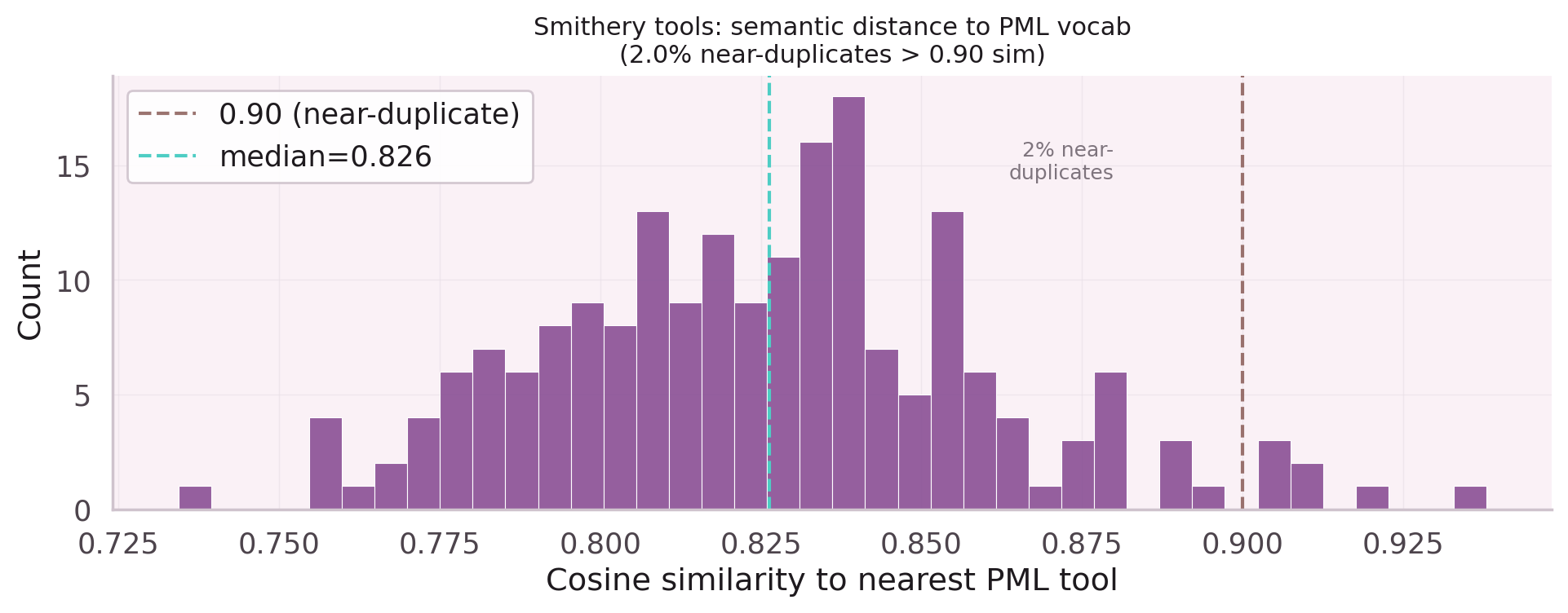
The Key Insight
The same leaf node can appear as std:psql_query, as
pml.mcp.std.psql_query.db48, or as pml.mcp.std.psql_query.3cd9
— three different strings for the same operation, varying only by instance hash.
Without normalization, these count as three distinct vocabulary entries.
The softmax over 2,160 "leaf nodes" includes 1,240 phantom duplicates.
normalizeToolId() collapses all three to std:psql_query.
Vocabulary drops from 2,160 to 920. Softmax concentrates. Hit@1 goes up.