What Didn't Work
The roads not taken. Five ideas that failed.
Negative Results Are Results
Five notebooks document failed approaches. Each one taught something useful — either about the data, about the model, or about what assumptions were wrong. They are not regrets. They are the map of the space.
Message passing implemented manually on a toy 5-node graph to validate the gradient computation before scaling. The toy problem worked — but the lesson was that 282 training examples are not enough for message passing to generalize. Wup and Wdown matrices require 1,000+ examples to learn meaningful projections. The manual implementation was abandoned for the attention-based approach.
Lesson: 282 examples is not enough for MP weight matrices.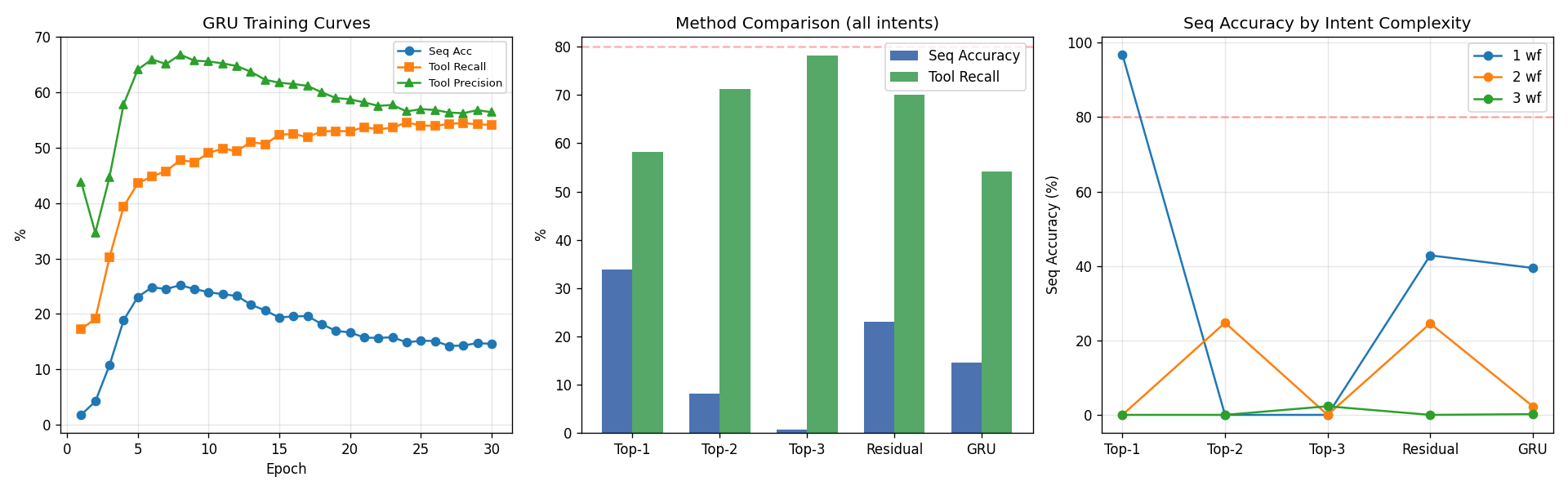
Attempted to scale the sequential graph GRU to larger datasets by increasing hidden dimension and adding layers. Training time grew quadratically; accuracy gains were marginal. The scaling law was unfavorable at this data size. Smaller and smarter (attention + residual) outperformed larger and naive.
Lesson: scaling parameters without data is just overfitting.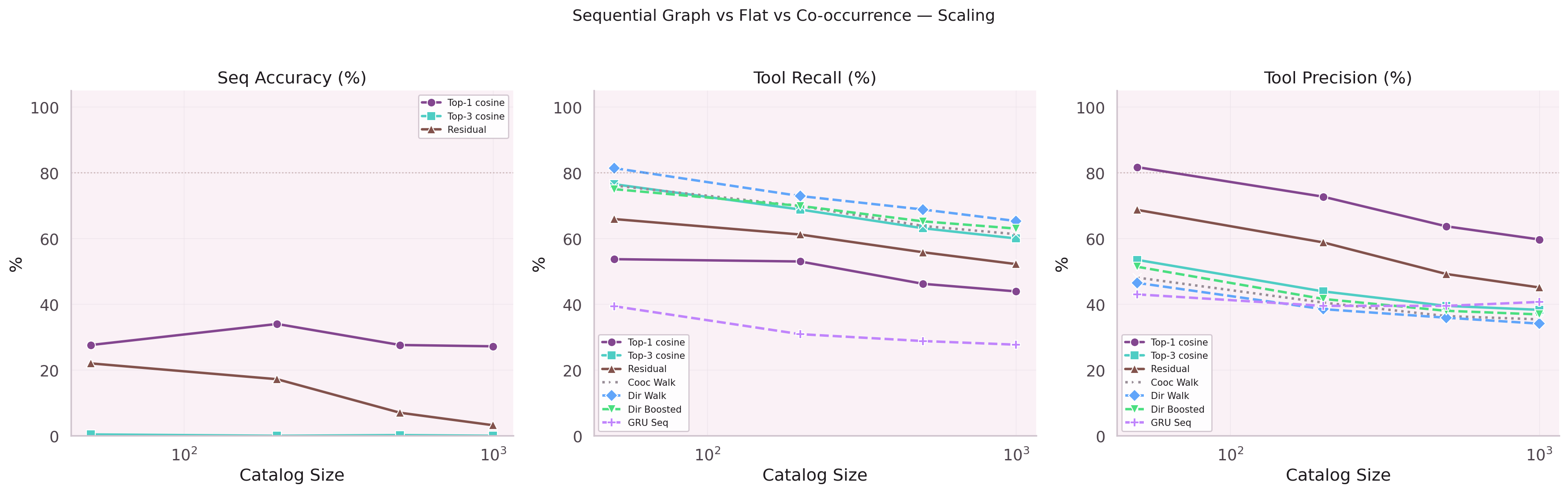
N8n workflow data was added to the training pool to compensate for the small production dataset. 12,000 n8n traces vs 4,600 production traces, with a weight of 0.3 and 3x oversampling for production. Result: Hit@1 dropped from 38.2% to 35.3%, MRR from 0.547 to 0.508, training time 4x longer. 60% of n8n data is Smithery noise; it expanded the vocabulary with 1,240 phantom nodes and diluted the production signal. The augmentation was removed entirely.
Lesson: noisy data at high volume beats clean data at low volume — in the wrong direction.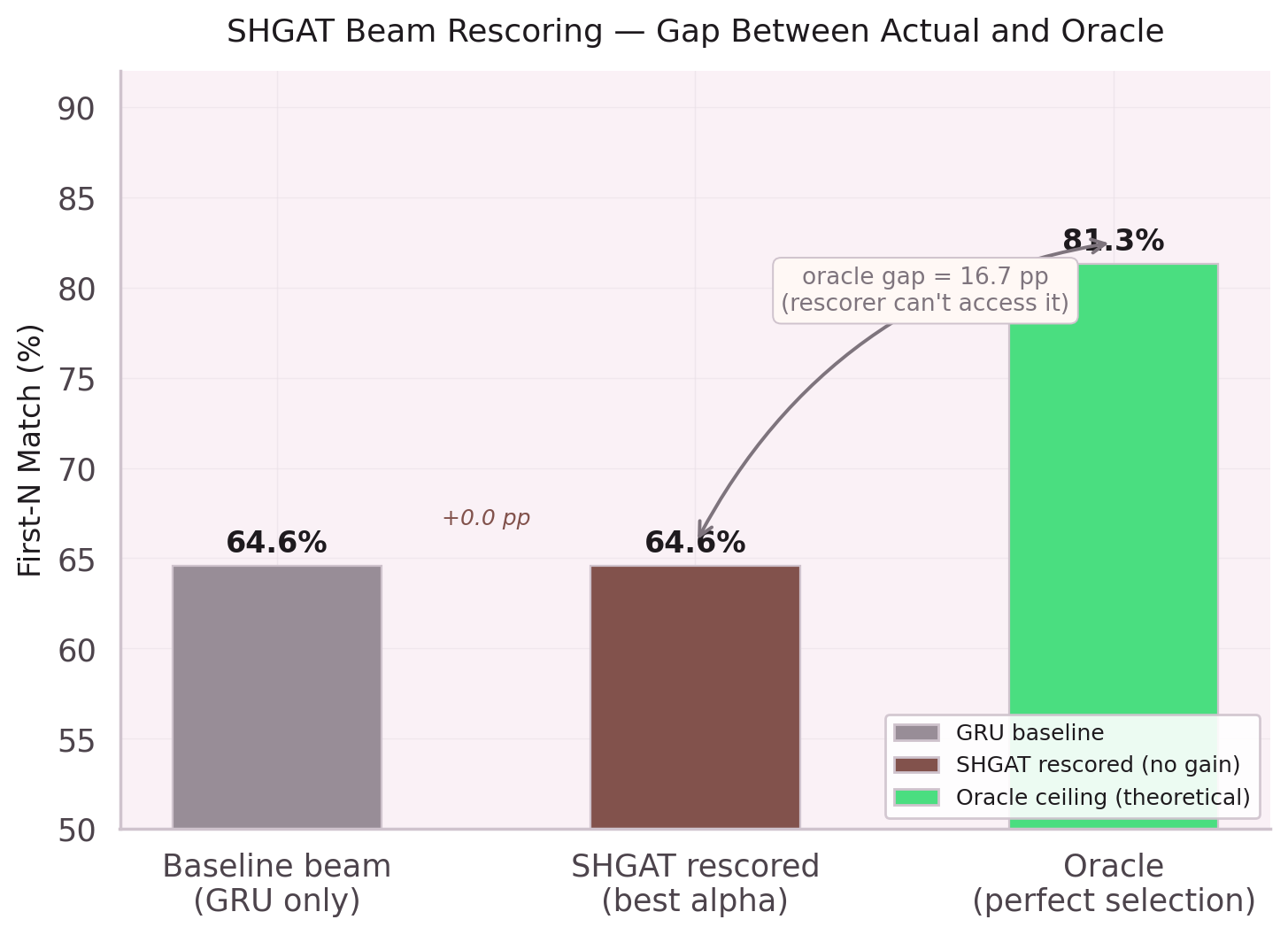
Instead of predicting the next node directly, the model would predict a centroid in embedding space, then retrieve the nearest vocabulary entry. This would generalize to unseen nodes without retraining. 104 nodes are multi-cap (belonging to multiple parent nodes), and 324 pairs are SHGAT-similar — the centroid idea had surface appeal.
In practice: centroid inference produced worse Hit@1 than direct prediction on every test configuration. The retrieval step introduced irreducible error. Not recommended.
Lesson: centroid inference loses to direct classification at this vocabulary size.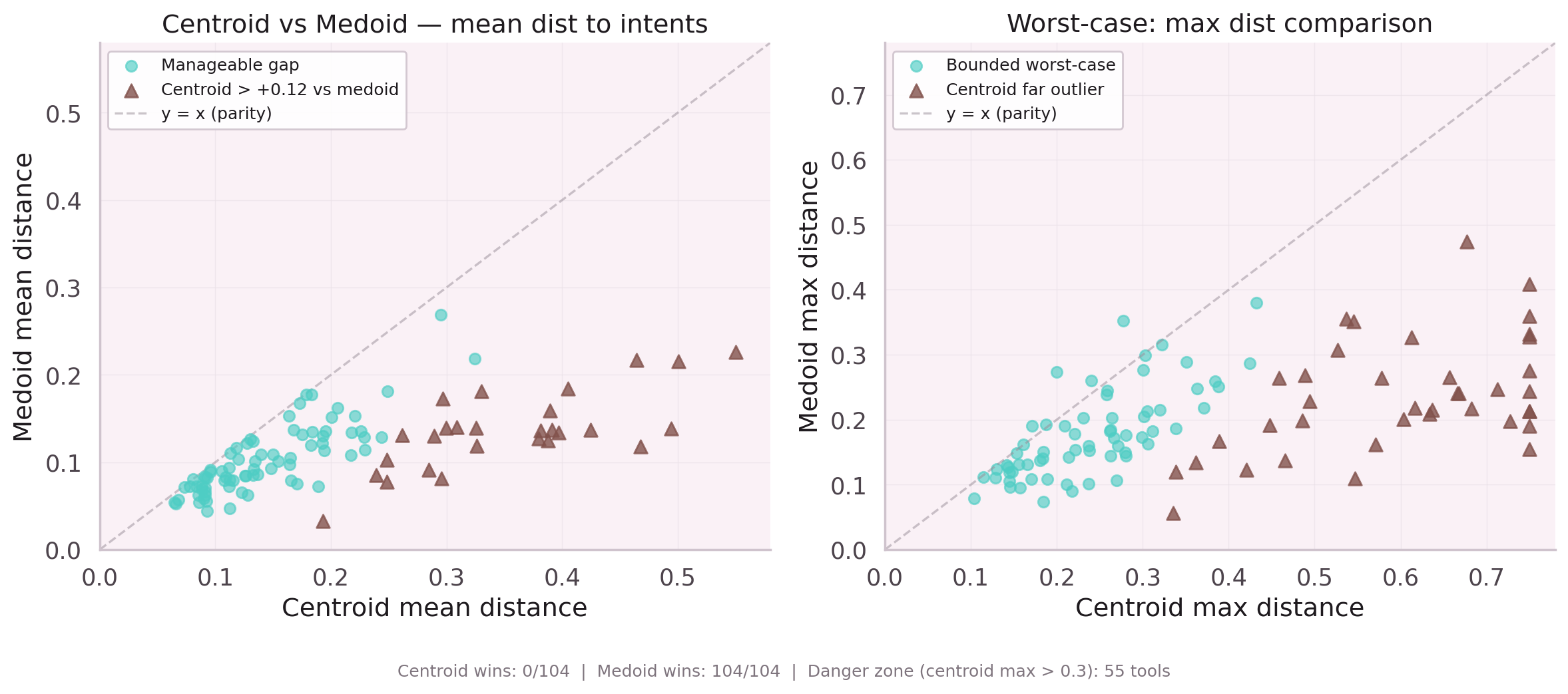
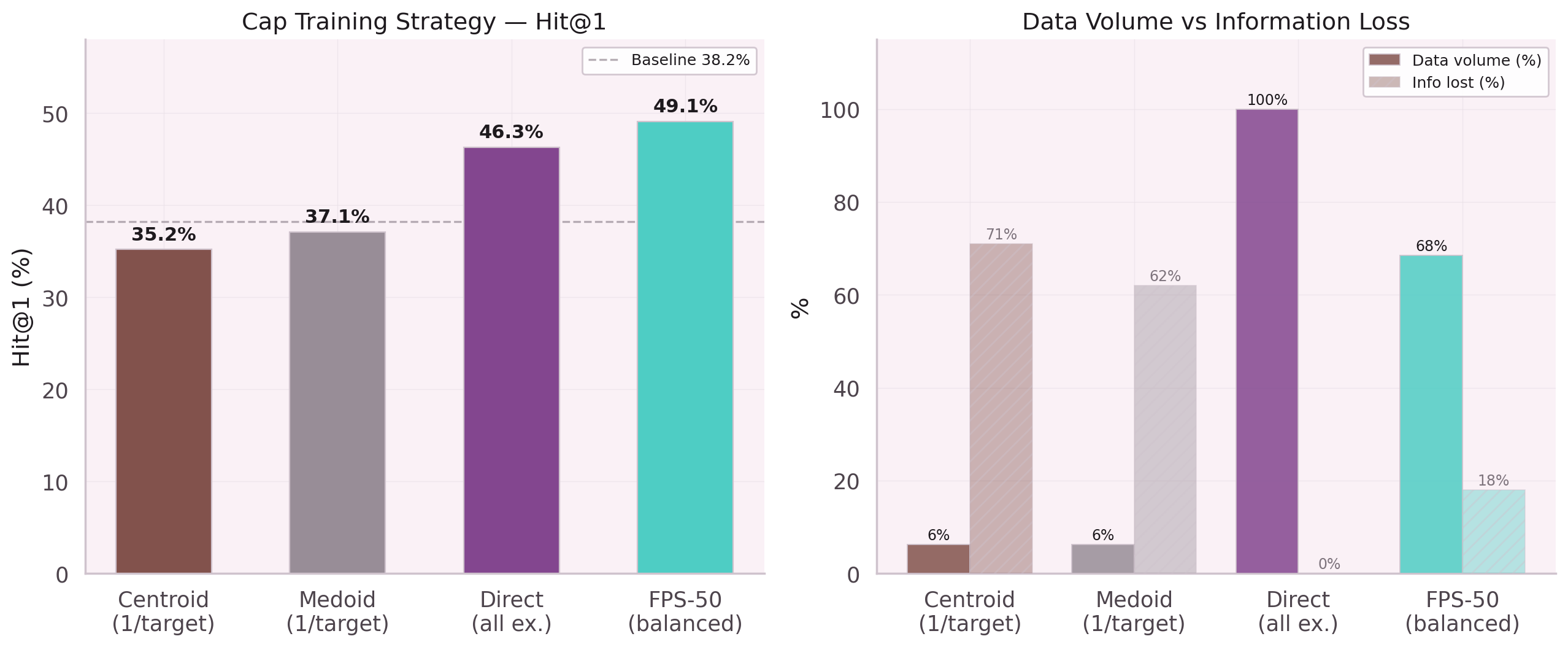
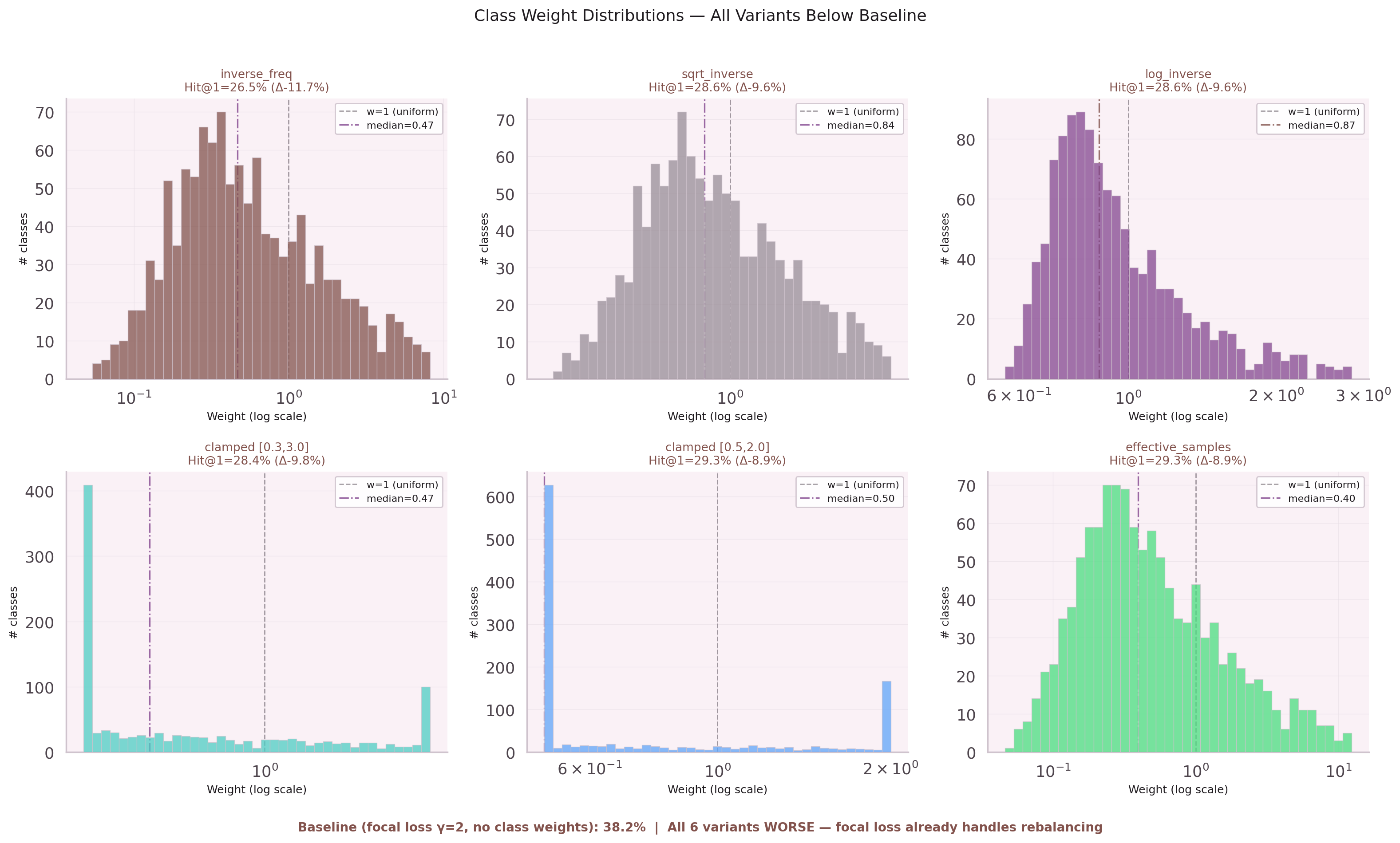
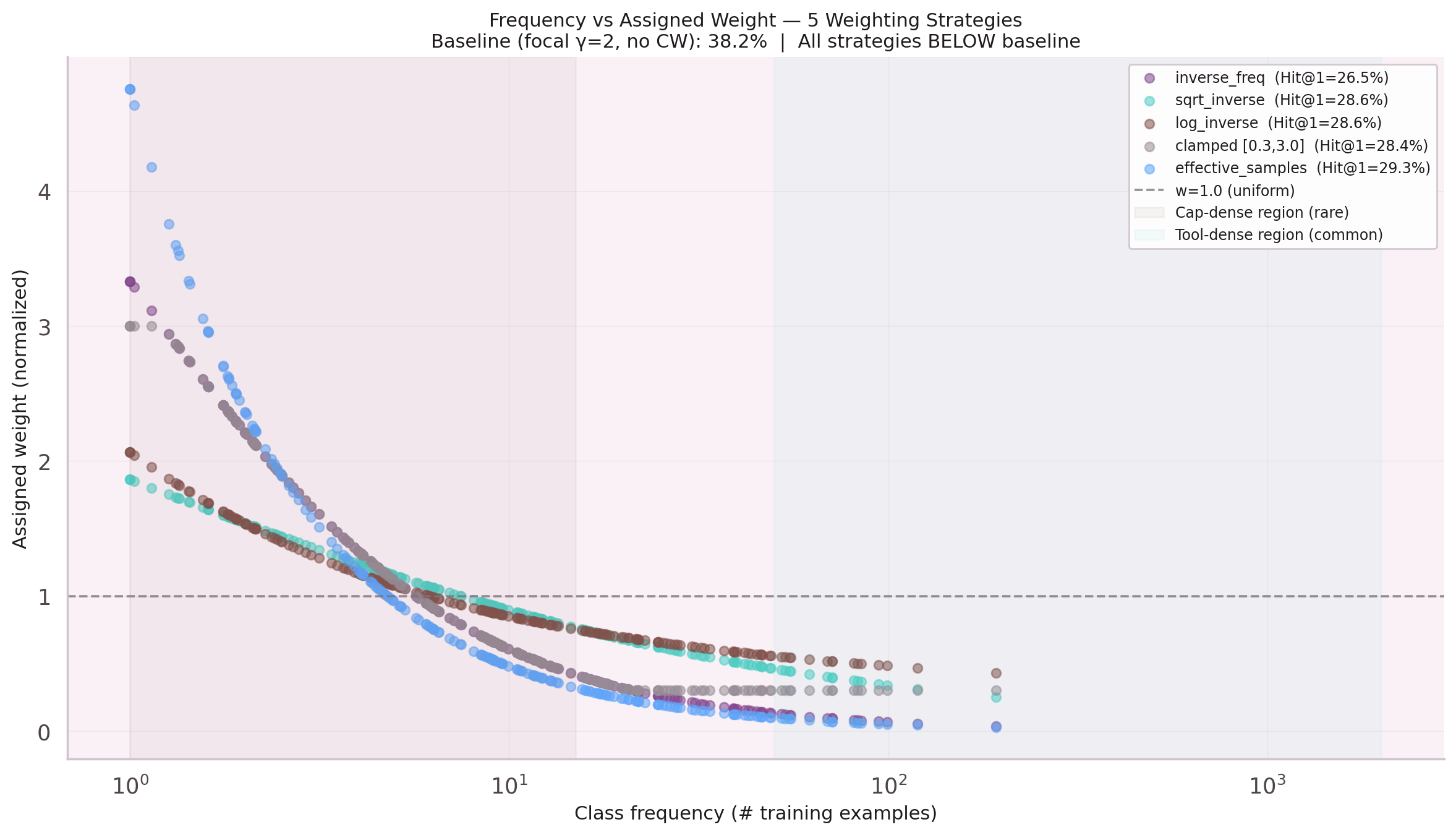
Five variants of class-weighted CE loss were tested: inverse frequency, sqrt-weighted, sqrt + frequency cap, no focal, and source-based weights. All five performed worse than the baseline 38.2%.
The root cause: the existing focal loss (γ=2) already handles class rebalancing adaptively. Adding static class weights created double-penalty for rare classes. Cap Hit@1 collapsed from 40.5% to 10–13% across all variants. Tool Hit@1 improved by 2pp — but the cap regression was catastrophic.
Lesson: focal loss γ=2 = adaptive rebalancing. Do not stack static weights on top.