Nodes All The Way Down
Unified vocabulary — leafs AND parents predicted by the same model.
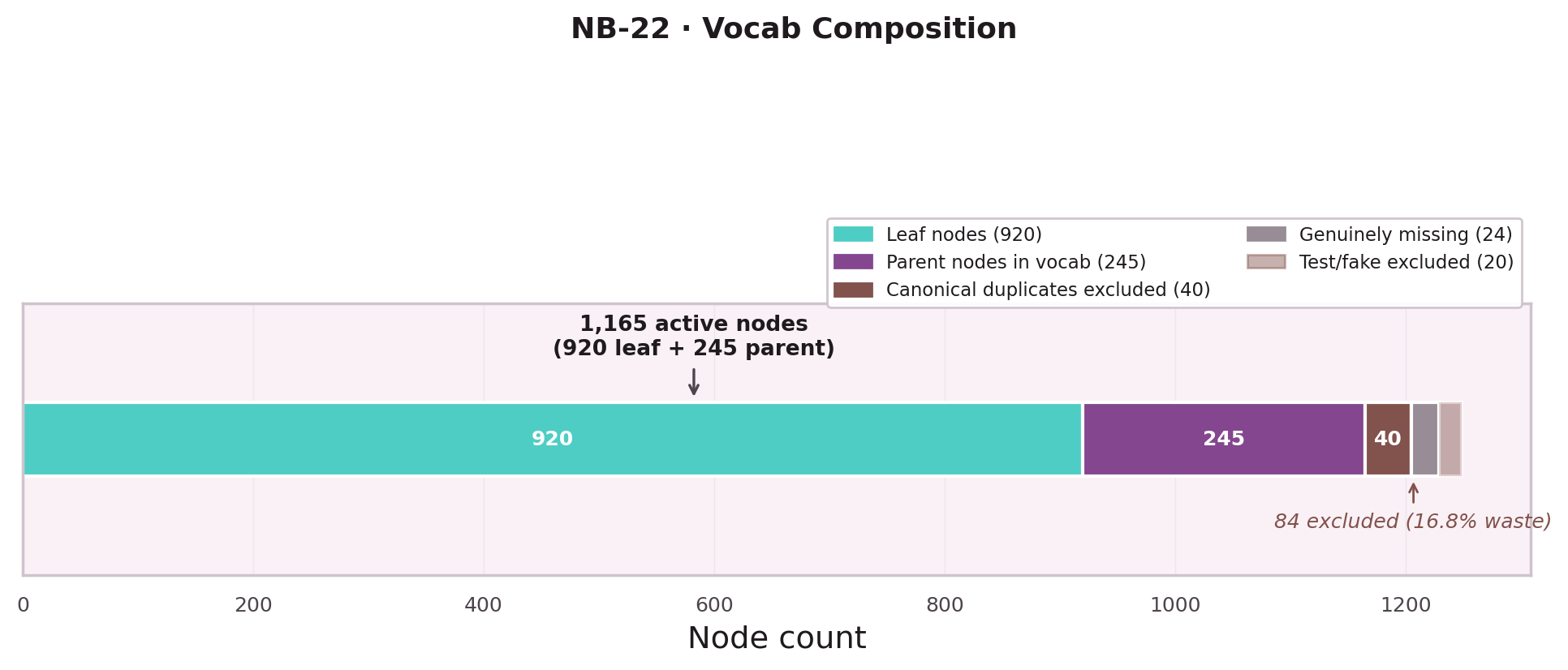
The Vocabulary Problem
A naive GRU predicts from a flat list of 920 leaf nodes. But execution traces contain more than leaf nodes: they contain parent nodes — named sequences of leaf nodes that recur across workflows. Ignoring parent nodes means the model never learns to predict "I need a database operation" before predicting the specific leaf node.
Five notebooks trace the discovery that leaf nodes and parent nodes must share a single vocabulary, and the consequences of that decision.
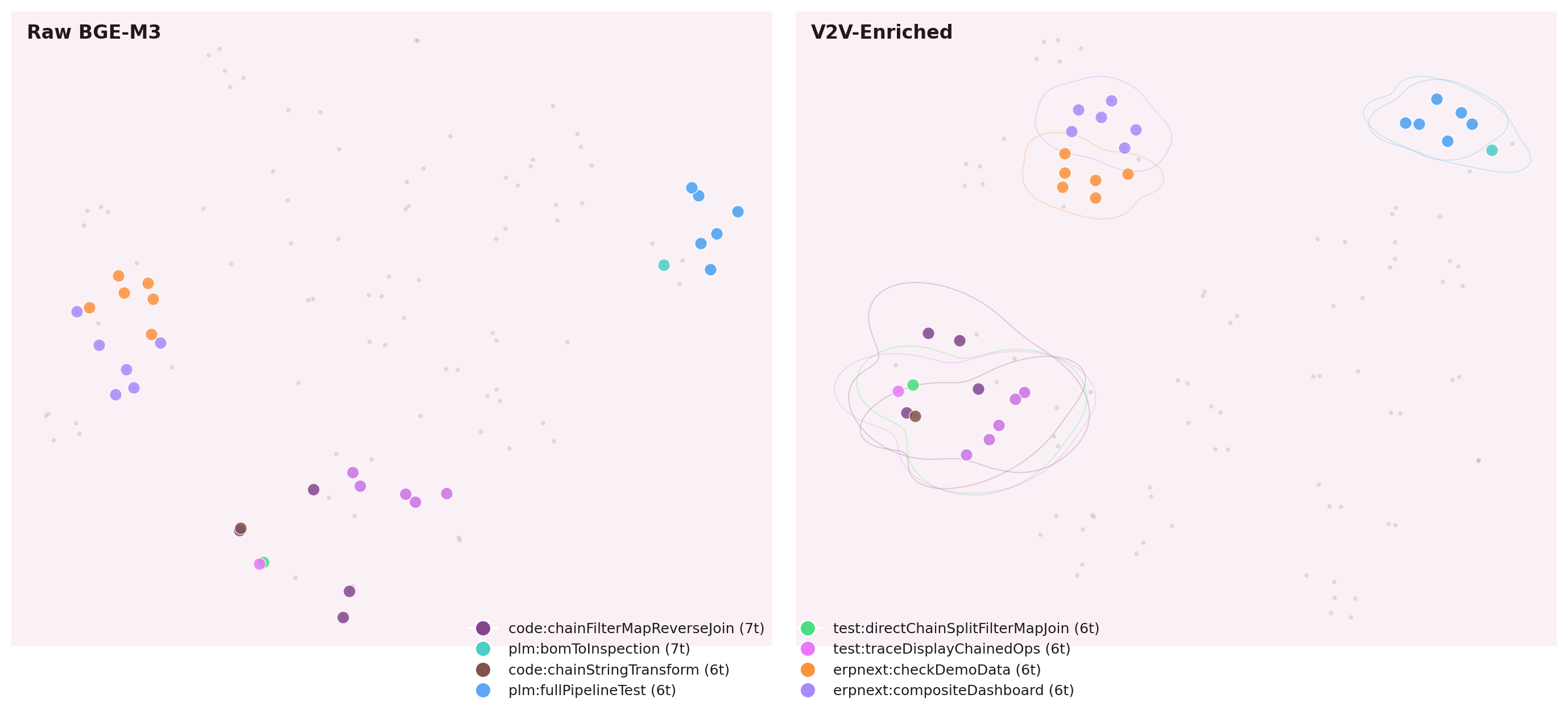
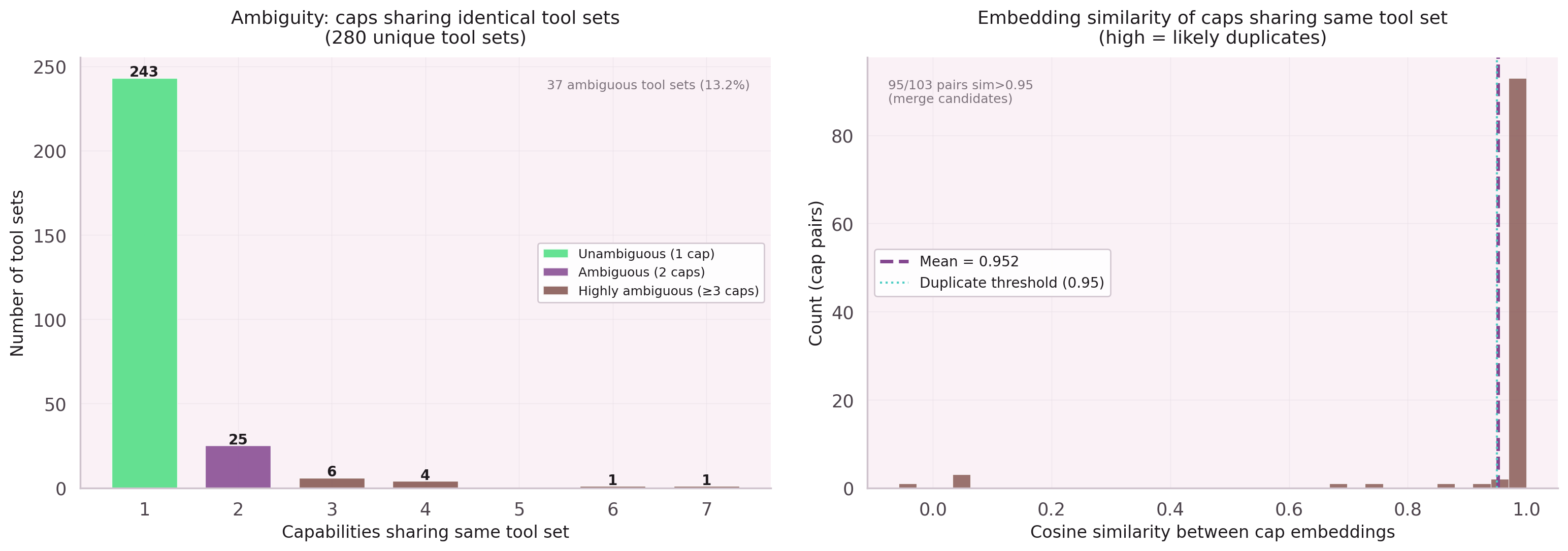
The Canonicalization Breakthrough
The softmax had a hidden enemy: 28 duplicate leaf-node groups, each generating
a separate parent node entry. A parent node named std:cap_rename
and another named code:cap_rename were the same logical operation
split across two vocabulary slots.
Canonicalization at training time — without touching the database — collapsed 71 duplicate parent nodes to 240 canonical entries. The softmax signal concentrated. Parent node Hit@1 jumped from 40.6% to 66.3%, a +25.7pp gain from deduplication alone.
Do not merge duplicates in the database. Canonicalize at training time. The database stores truth; the model trains on a view.
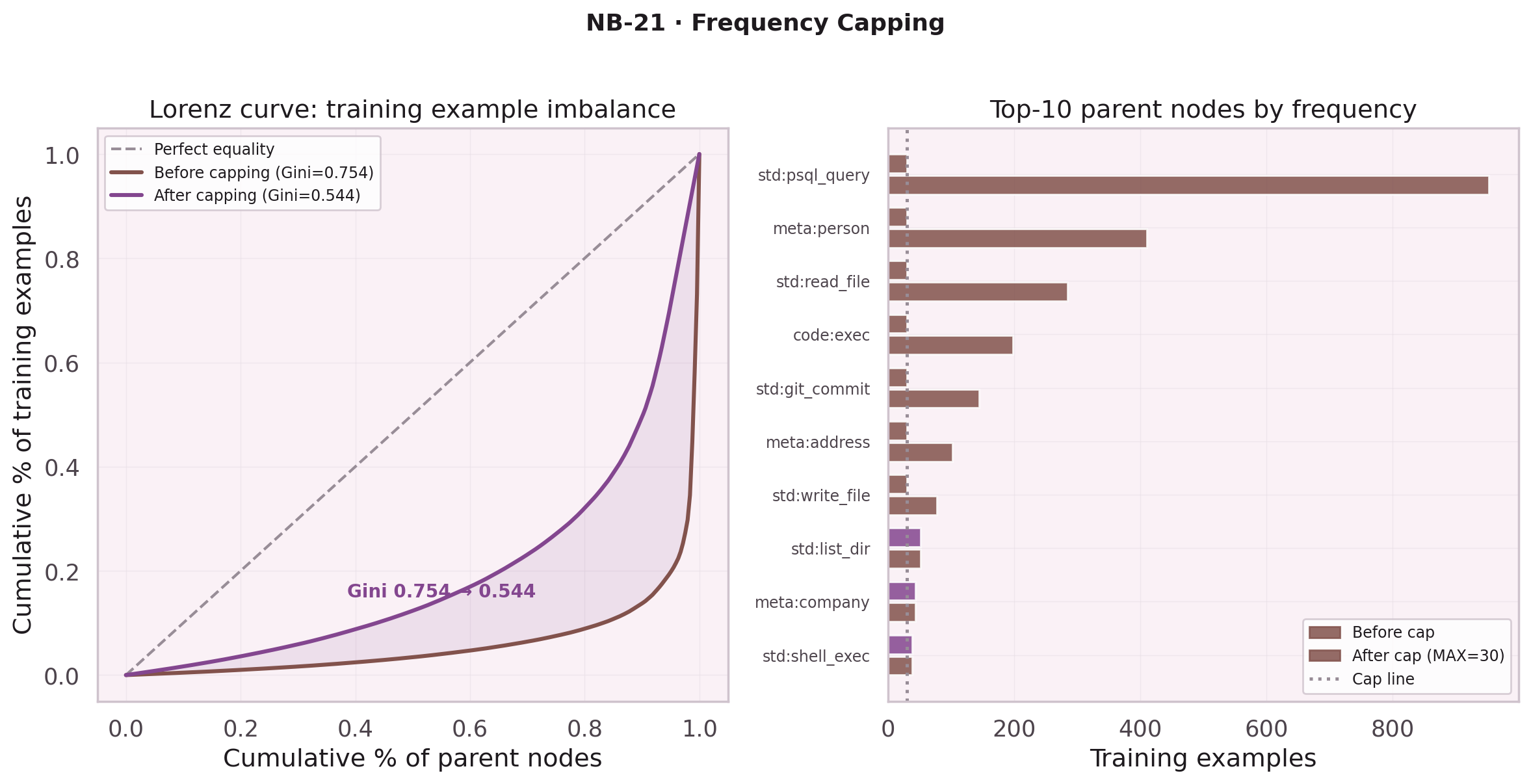
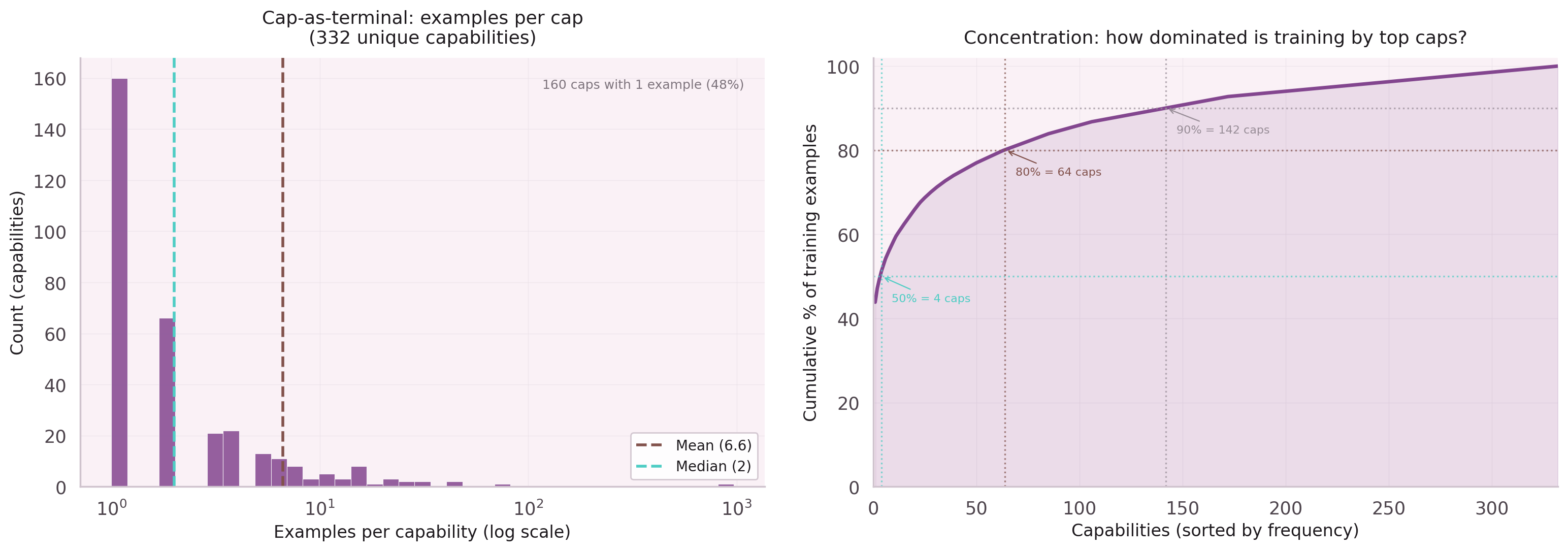
Frequency Capping with FPS
Some parent nodes dominate the training set: std:psql_query
appears in thousands of traces. Without capping, the model learns to predict
the most common leaf nodes regardless of context.
NB-21 evaluated two capping strategies: random subsampling versus Farthest Point Sampling (FPS). FPS selects the most diverse subset by maximizing distance in intent embedding space, producing a training set with mean pairwise similarity 0.62 vs 0.68 for random — better coverage of the intent distribution with the same budget.
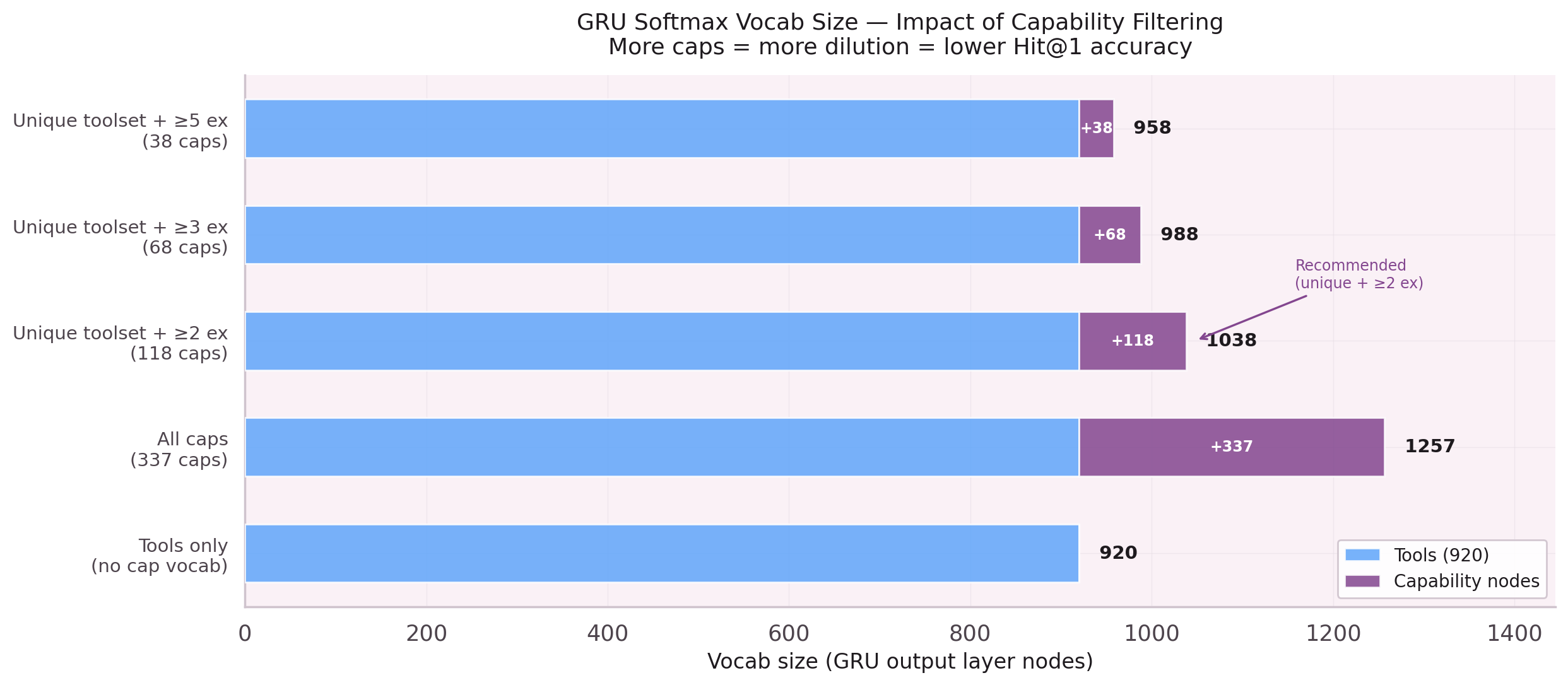
NB-22 revealed the cost: MAX_PER_CAP=30 raises parent node Hit@1 to 82.3%
but drops leaf node Hit@1 from 49.3% to 37.2%. The capping was too aggressive.
The search for the right cap value continues.