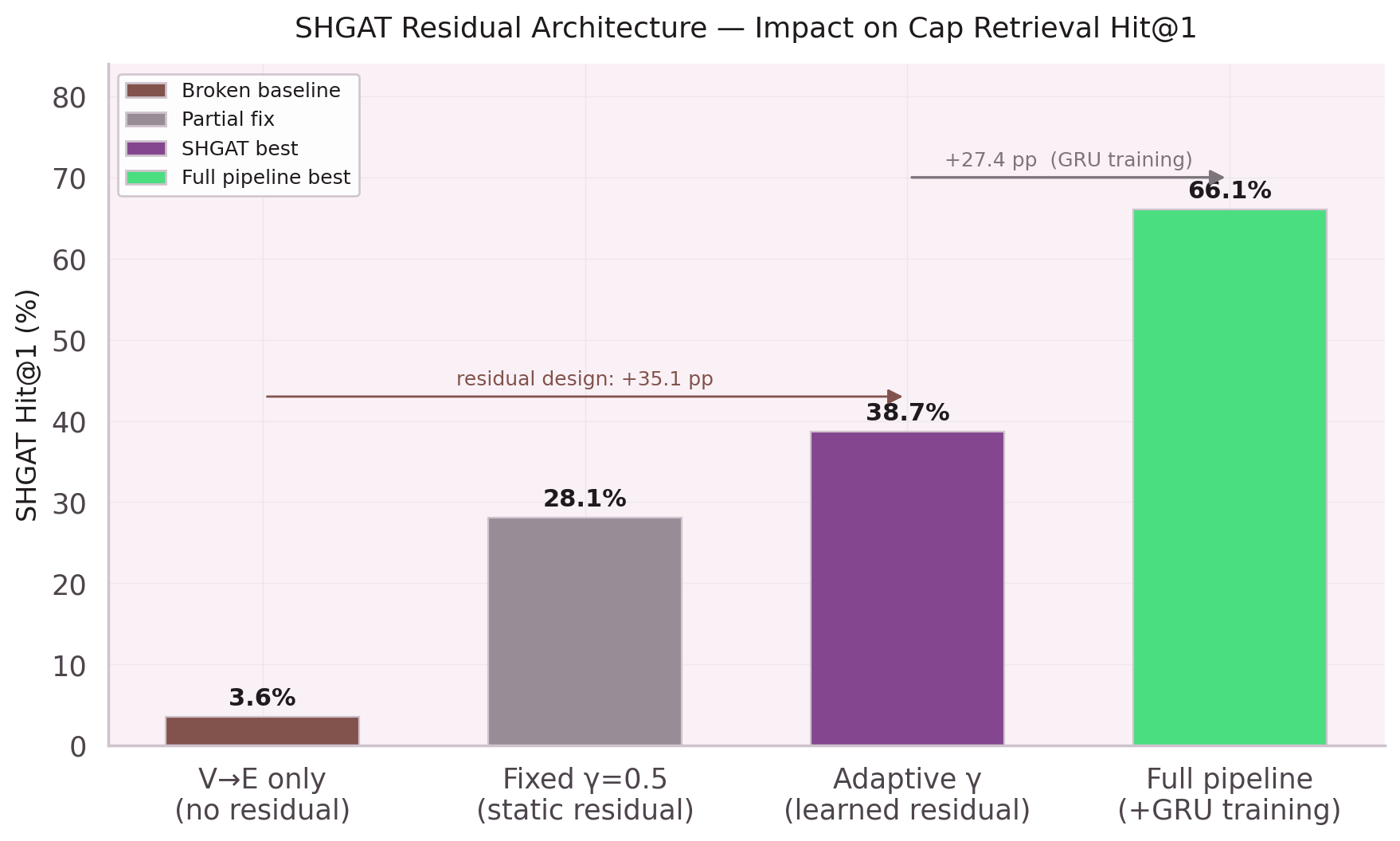
Two Parameters, +22.7pp
The residual connection changed everything.
The Problem with Message Passing
Standard graph neural networks replace each node's embedding with a weighted average of its neighbors. For dense graphs this works well — nodes have many neighbors to average over, producing stable representations.
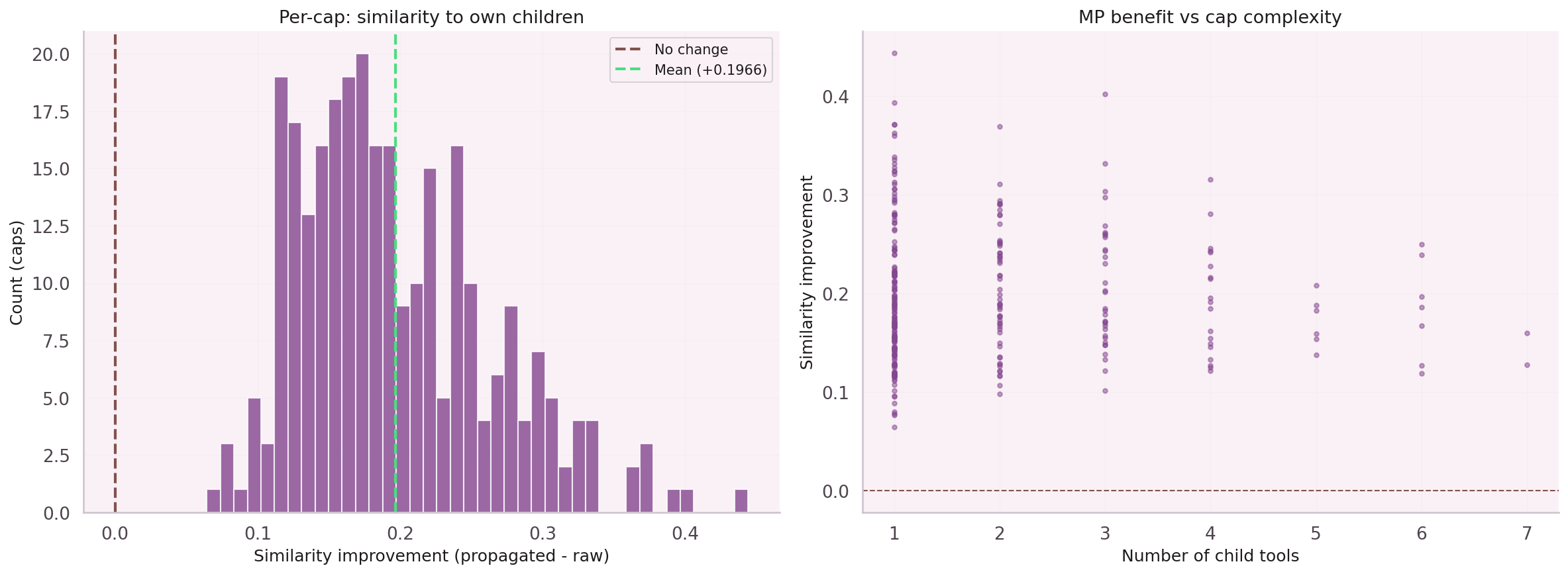
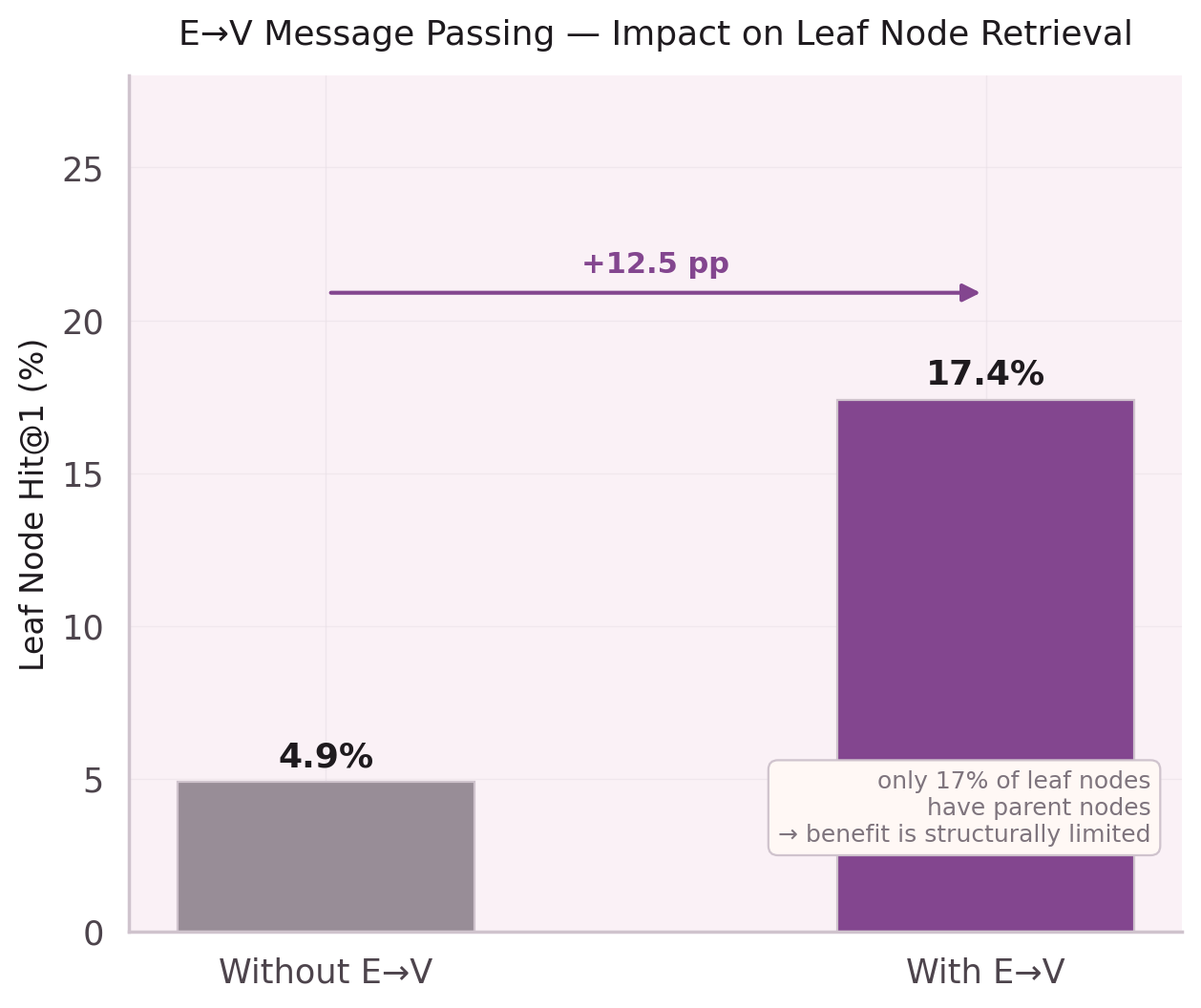
For sparse graphs — like a node co-execution graph where the average node degree is 4.7 — aggregation destroys information. A node with two neighbors becomes an average of those two neighbors, losing its own identity entirely.
The Four Notebooks
The residual was not invented in one step. Four notebooks trace the path from the initial observation (NB-12) to the final parameterization (NB-16).
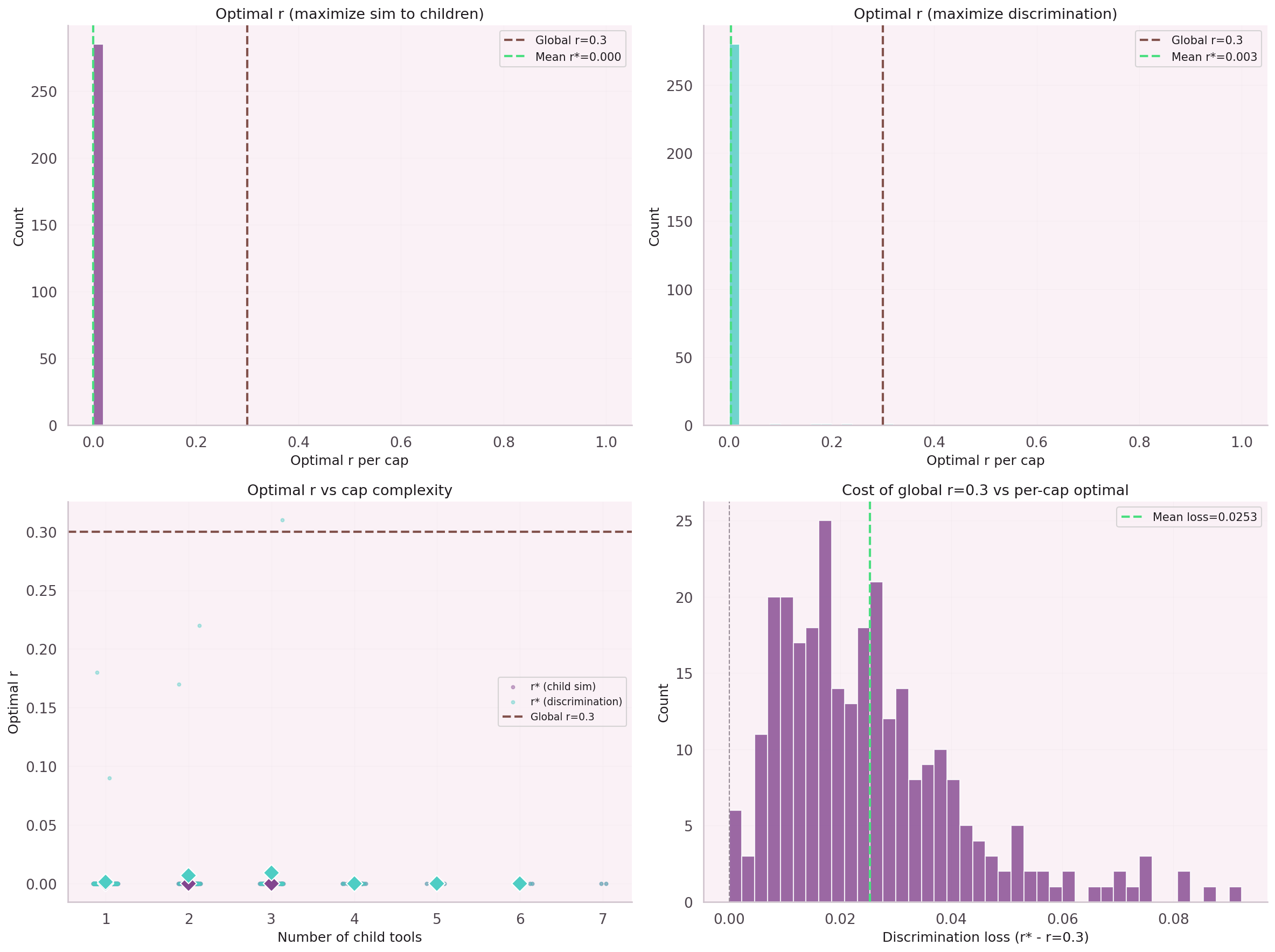
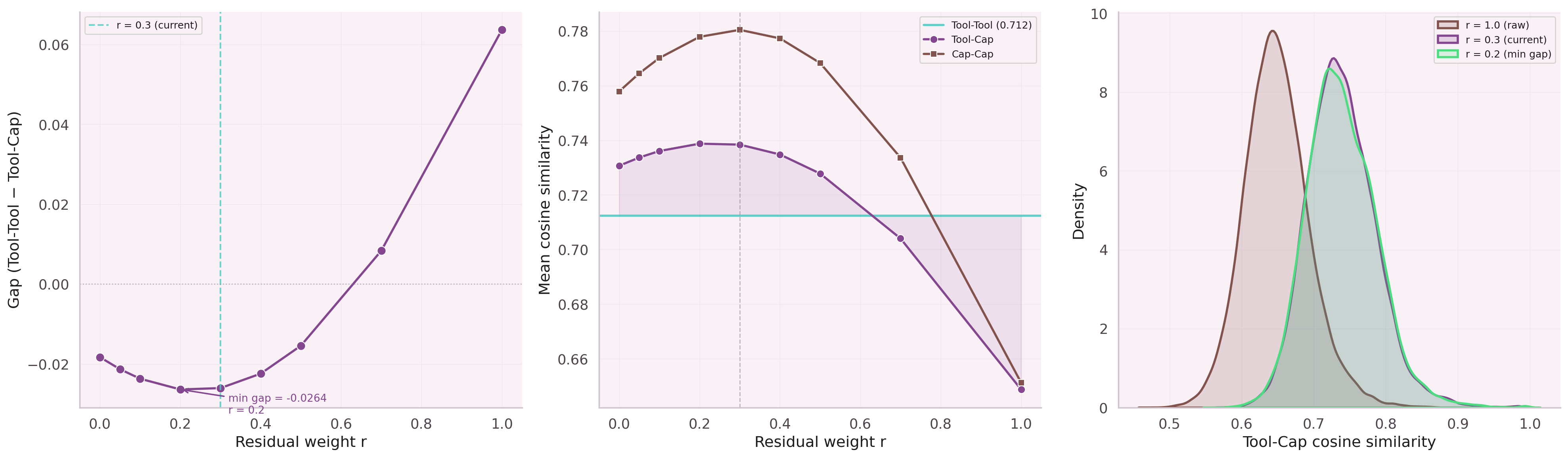
First experiment: add a skip connection with a fixed weight α. Result: α=0.99 is a no-op, α=0.5 collapses representation quality. No static weight works across the full degree distribution.
The weight must be a function of degree, not a constant. Grid search over initialization values for a and b. Optimal init: a=−1.0, b=0.5 — γ starts near 0.5 and learns from there.
Hit@1 at epoch 0: 38.3%. At epoch 10: 59.0% (best checkpoint). Early stop at epoch 12. The residual parameters converge in the first 5 epochs, after which the rest of SHGAT fine-tunes around them.
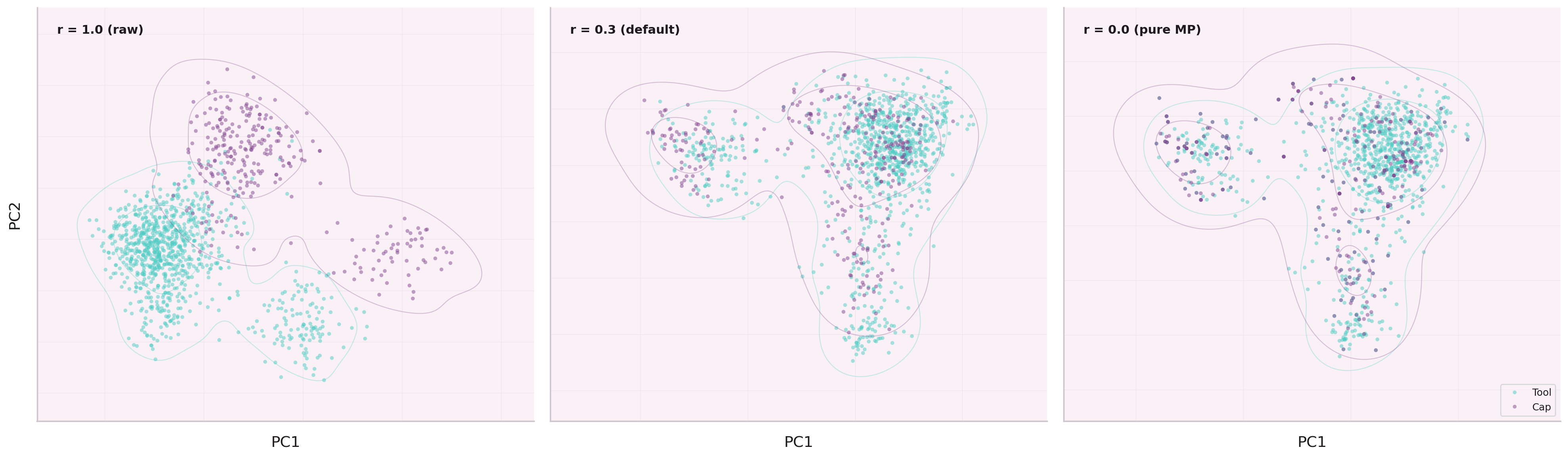
Final architecture: the residual is applied post-concat-heads in the multi-level orchestrator, at embDim=1024 (not per-head). The V→E code path is separate from the standard forward pass.
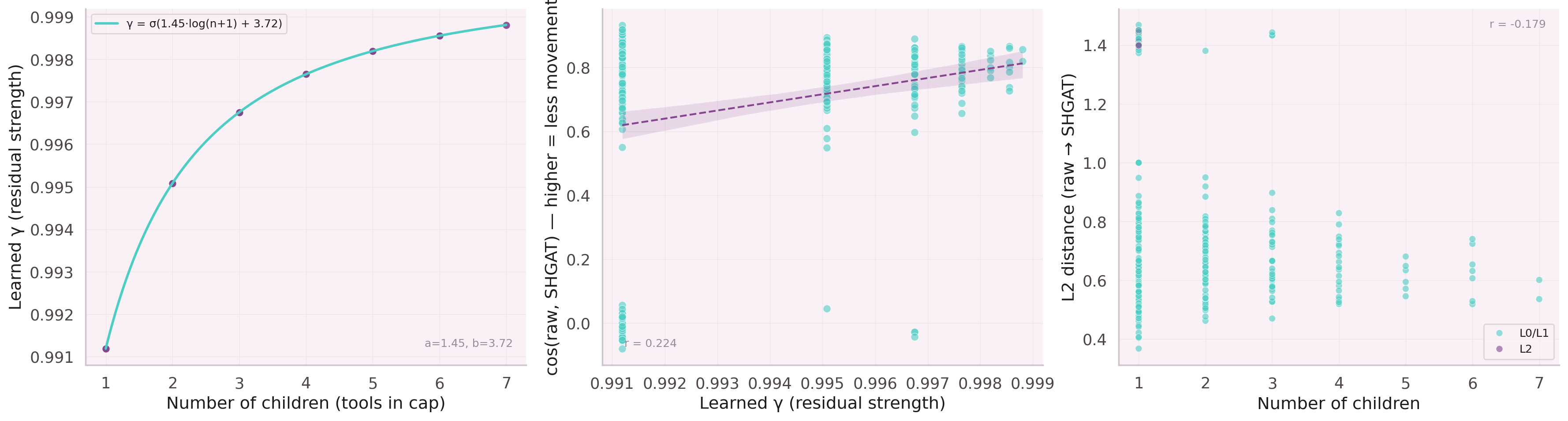
What the Model Learned
After training, the learned γ(n) function was inspected. Nodes with 1–3 children (sparse leaf nodes) retain ~80% of their original embedding. Hub parent nodes with 10+ children blend down to ~40%.
The model discovered the right tradeoff without being told. The initialization provided a reasonable starting point; the gradient did the rest. Two parameters. Thirty epochs. Twenty-two points.